Double Descent Explained: Why More Data Can Make a Model Worse
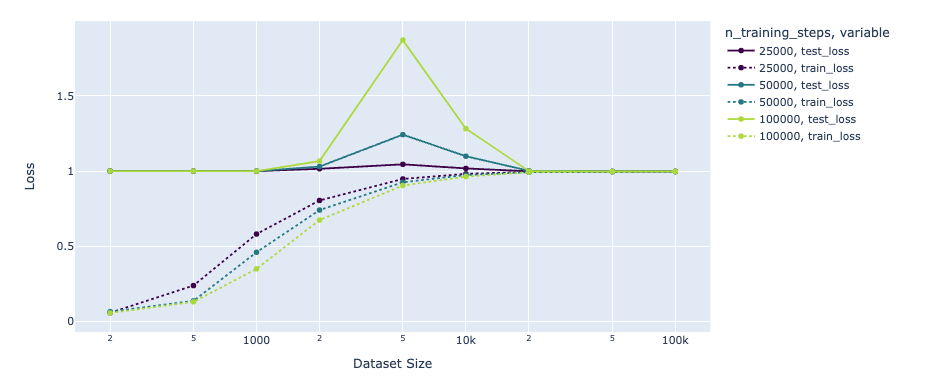
One of the strangest facts in deep learning: adding more data or more capacity can make a model worse before it gets better. Test error falls, then rises into a bump, then falls again — the famous double descent curve. Anthropic's toy-models work gives this puzzle a clean, mechanistic explanation, and it runs straight through superposition.
A refresher: superposition
Recall the key idea from Toy Models of Superposition: a network can store more features than it has neurons by overlapping them in shared, nearly-perpendicular directions — cheap, because sparse features rarely fire at the same time. Features compete for a limited budget of representational space.
The key reframe: memorized points are "fake features"
Here's the move that unlocks everything. A memorized training example behaves, mechanically, just like a feature stored in superposition. So memorizing the training set and representing genuine features are drawing on the same limited budget. Memorization and generalization are in direct competition for room.
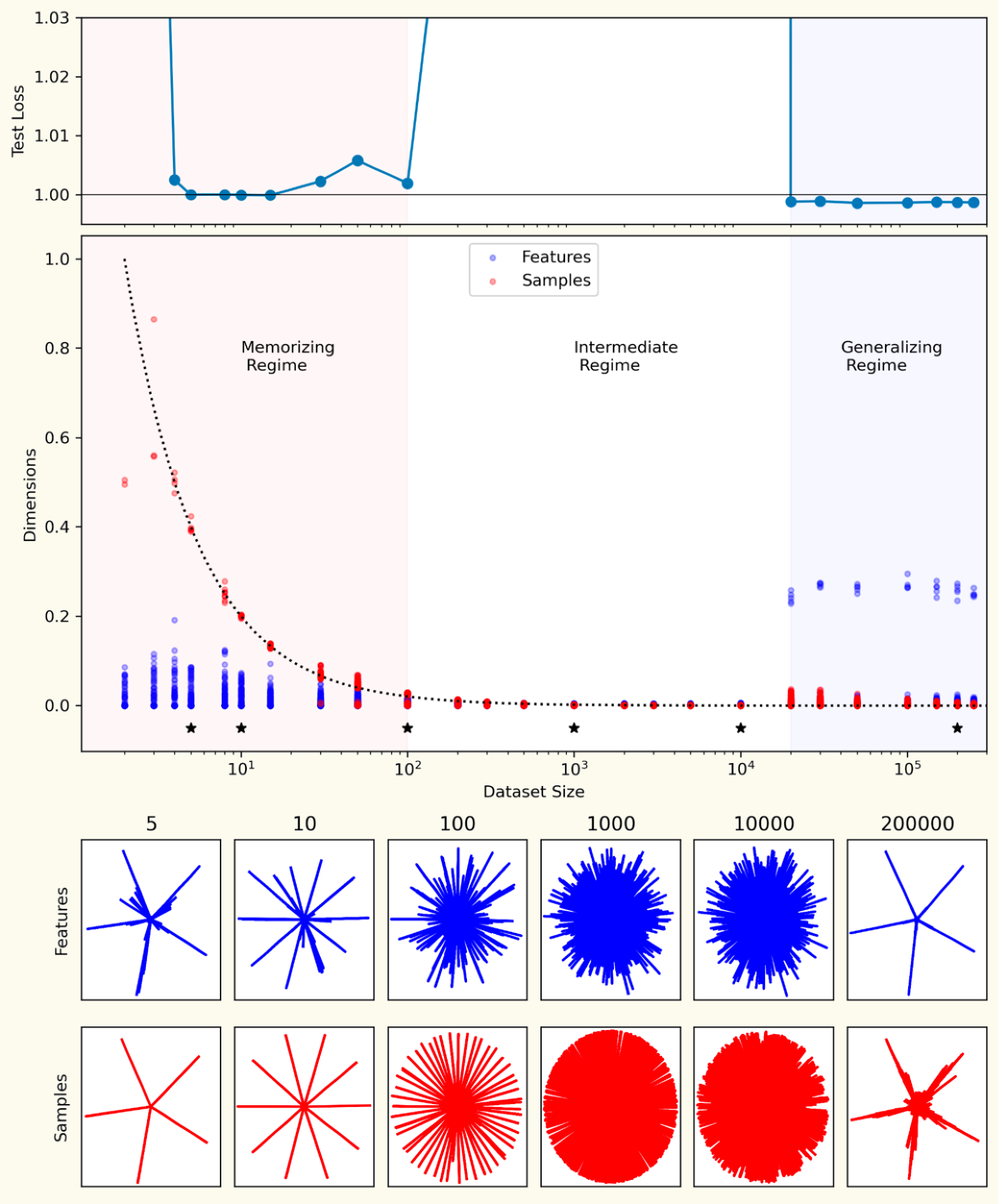
Where the bump comes from
That competition is the bump. When you have roughly as many parameters as data points, the model is torn between two regimes — memorizing individual examples and encoding general features — and does neither well. That awkward crossover is exactly where test error peaks.
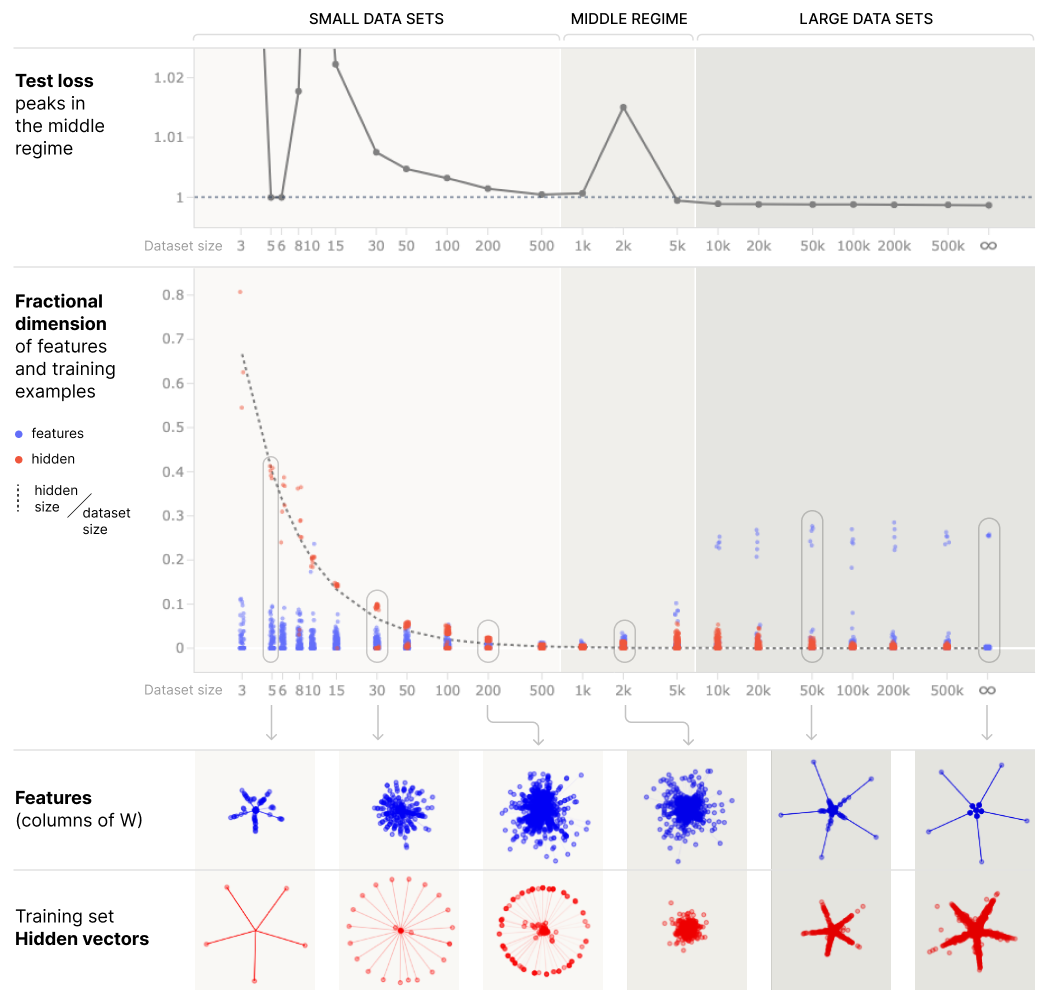
Add more data (or capacity) and the balance tips decisively toward general features; the interference clears, and error drops again — the second descent.
Measuring the tug-of-war
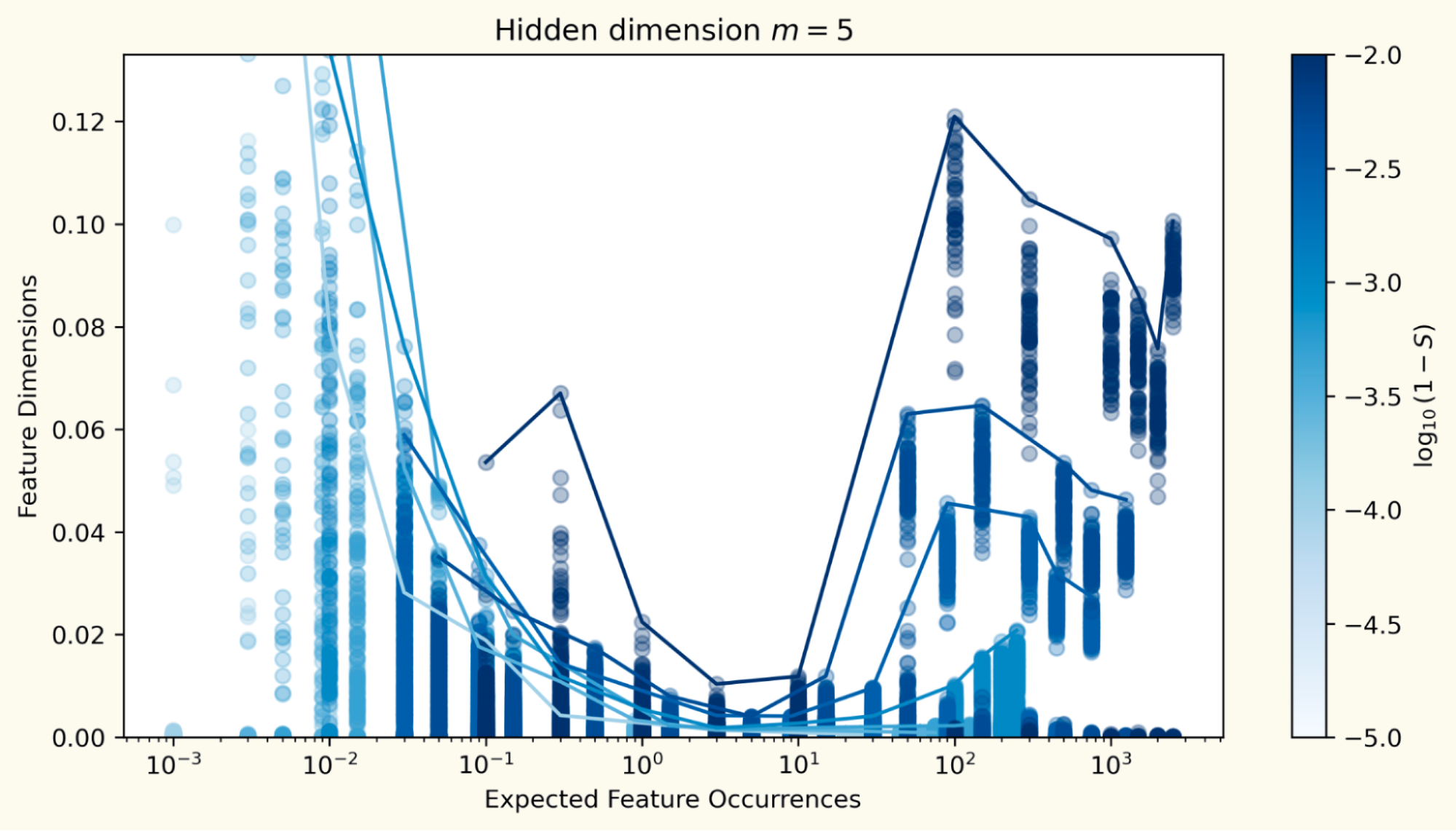
Using feature dimensionality — how much representational room each thing claims — you can literally watch the tug-of-war: as the regime shifts, the geometry reorganizes, and the loss responds. The toy model reproduces the double-descent bump and explains it, in a system simple enough to inspect completely.
Why interpretability cares
Double descent isn't a paradox to be memorized — it's a regime change, a fight over a finite feature budget made visible. That reframing matters: it ties one of the field's most confusing empirical curves directly to superposition, the same mechanism behind polysemantic neurons. Understand how a network packs features, and phenomena that looked like deep-learning black magic start to look like geometry.
The usual caveats apply — it's a deliberately small toy model — but the explanatory payoff is large: a famous mystery, demystified by the same idea that's reshaping interpretability.
Source: Henighan, Olsson et al., "Superposition, Memorization, and Double Descent," Anthropic — Transformer Circuits Thread (2023). All figures © the authors, shown here for educational explanation.
Cite this post
Auto-generated. Verify for your institution's requirements.