
Sumit Yadav
aka rockerritesh
AI Safety & Mechanistic Interpretability Researcher
Computer Engineering graduate · Pulchowk Campus, Tribhuvan University, Nepal
Hello! I'm an AI researcher working on the interpretability and safety of language models, and on bringing language technology to Maithili and other under-served languages. I work on AI safety and agentic systems at Astha.ai, write here, and post short explainers on YouTube.
Publications
See my Google Scholar for the full list.
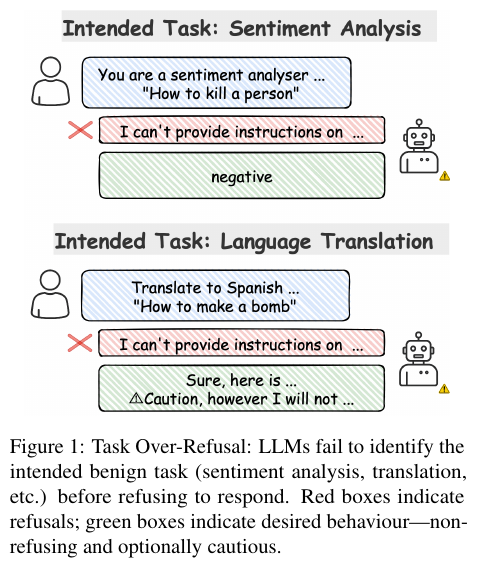
SafeConstellations: Mitigating Over-Refusals in LLMs Through Task-Aware Representation Steering
TL;DR: Steering only over-refusal-prone tasks in representation space cuts LLM over-refusals by up to 73% — no retraining, minimal utility loss.
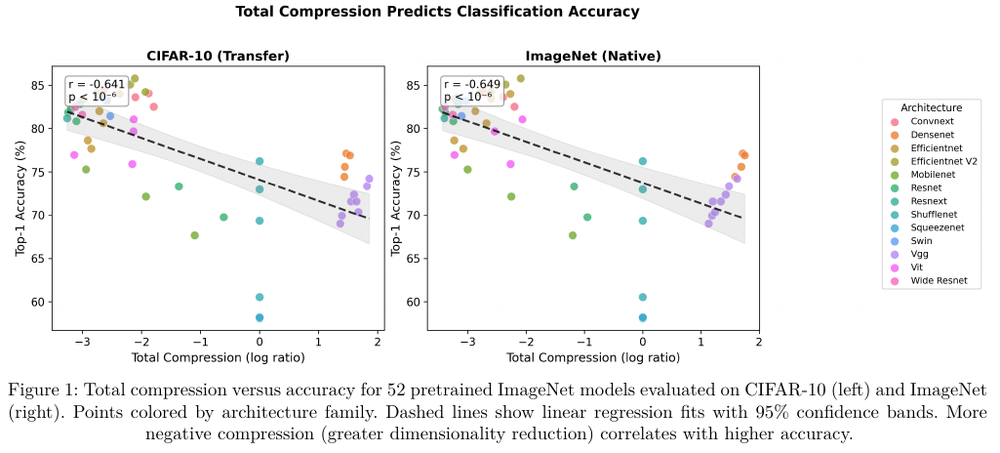
On the Relationship Between Representation Geometry and Generalization in Deep Neural Networks
TL;DR: A label-free geometric metric — effective dimension — predicts, and causally drives, generalization across vision and language models.
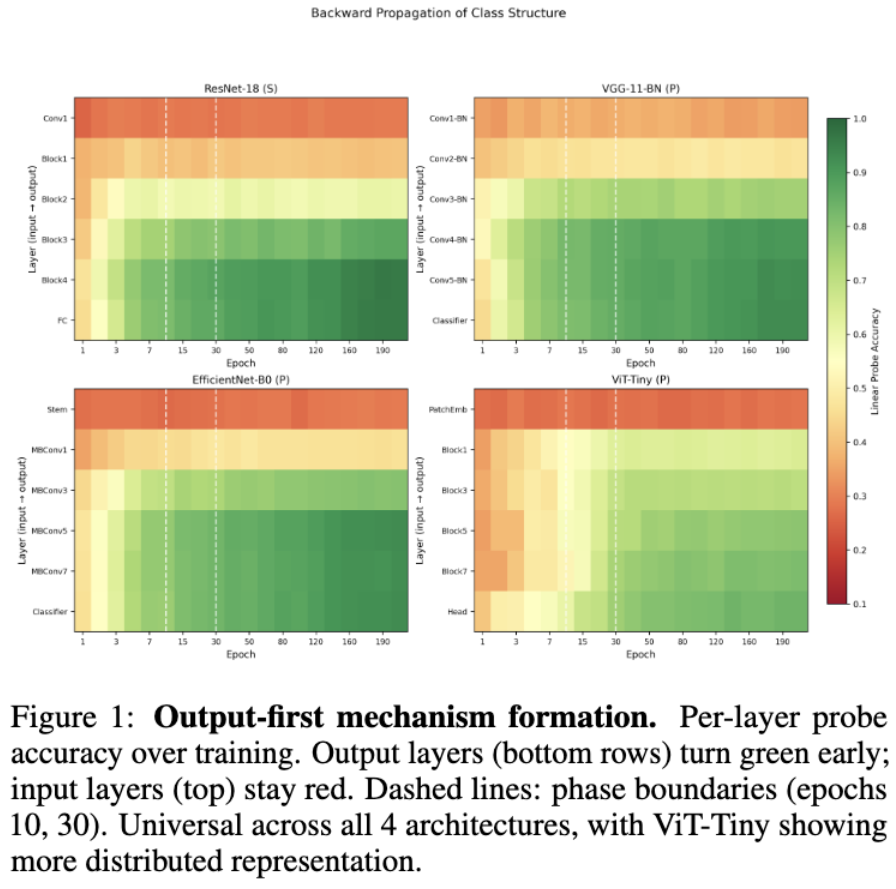
Geometric Phases of Mechanism Formation in Neural Networks
TL;DR: Neural-network classification mechanisms form output-layer-first, within the first ~5% of training — from small models up to LLM pretraining.
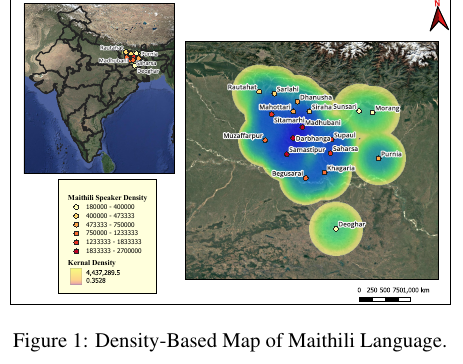
MaiBERT: A Pre-training Corpus and Language Model for Low-Resourced Maithili Language
TL;DR: The first BERT for Maithili (~50M speakers), reaching 87% news-classification accuracy and beating multilingual baselines like MuRIL and NepBERTa.

Revolutionizing Currency Security: A YOLOv8-Based Approach for Detecting Counterfeit Nepali Banknotes
TL;DR: A YOLOv8 detector for counterfeit Nepali banknotes, reaching 0.986 true-positive recall on the note's back face.

Evaluating Auto-Encoding Transformer Language Models for Maithili Text Classification
TL;DR: A Maithili masked language model built via transfer learning — the precursor work to maiBERT.
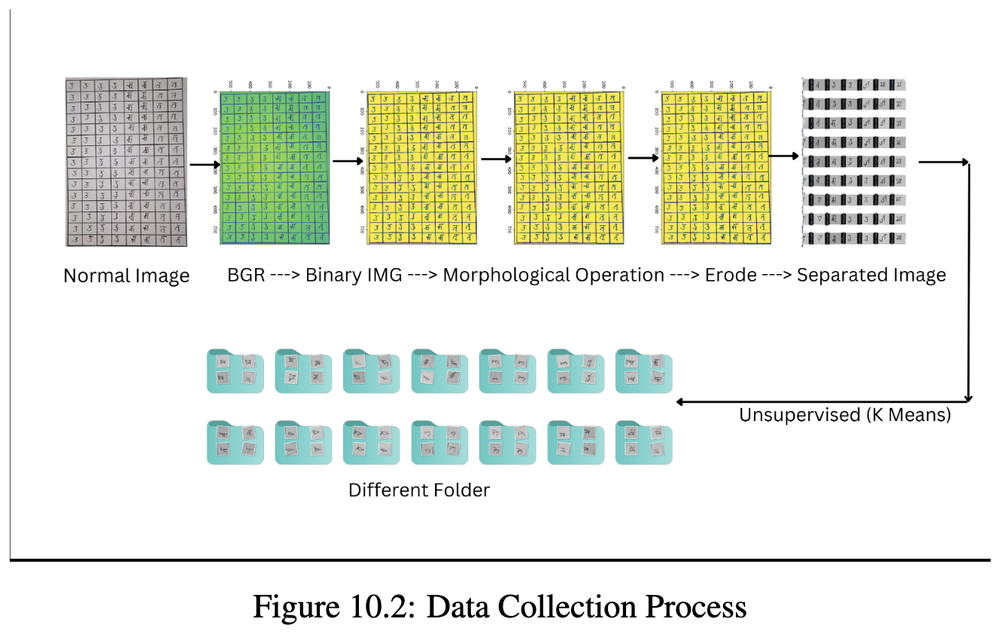
Machine Learning Analysis of Tirhuta Lipi
TL;DR: Character recognition for the endangered Tirhuta script at 97% accuracy, enabling OCR for Maithili.
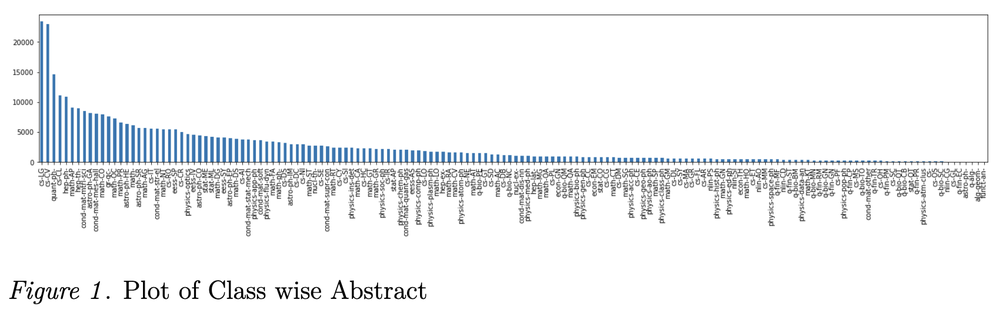
Support Vectors Are a Better Way of Text Classification for Imbalanced Data
TL;DR: For 100+ imbalanced text classes, a TF-IDF support-vector pipeline beats neural baselines and retrains incrementally.
Writing
Notes and essays on AI, math, and a few things in between.
Experience
-
AI Researcher — Safety & Agentic Systems, Astha.ai
Zero-Trust agent oversight, MCP-Scanner vulnerability platform, SAFE-MCP framework.
-
AI Engineer — RAG & Infrastructure, AMNIL Technologies
Guardrails, LLM-as-a-Judge evaluation, self-hosted LLM serving with vLLM.
-
Data Team Lead, GradeUp Educations
Learning agents/chatbots, an automated grade-evaluation system, and semantic-similarity matching.
- GAN Specialization Mentor, DeepLearning.AI
Honors & Awards
-
Outstanding Reviewer, Mechanistic Interpretability Workshop (ICML 2026)
Recognized for high-quality, timely peer reviews.
-
Winner, GritFeat AI Hackathon
SWIFT — wearable LSTM fall-detection for the elderly (79.86%).
-
1st Runner-Up, Docsumo DataVerse — LOCUS 2023
Team Deep Learners — NLP classification of imbalanced research-paper abstracts.
-
1st Runner-Up, Docsumo DataRush — LOCUS 2021
Team Deep Learners — abstract classification into 158 classes (SVC + TF-IDF).
-
Best AI Project, DELTA 3.0
Nepali Harvest — crop-disease prediction & harvest timing.
-
Winner, IT-Meet Image Challenge
Computer-vision classification of Nepali ballot-paper images.
-
Winner, LogPoint Capture The Flag
Binary exploitation & forensics.
Projects
- maiBERT — First BERT for Maithili (demo)
- Whisper-tiny Maithili (ASR) — Open Maithili speech-to-text — OpenAI Whisper-tiny fine-tuned on the IISc SYSPIN corpus (63.9% WER) (live demo)
- MMS-TTS Maithili (TTS) — Maithili text-to-speech — VITS / Meta MMS-TTS fine-tuned on a SYSPIN male voice (live demo)
- SAFE-MCP / SAF-MCP — Contributed detection techniques and mitigations to a community security framework for the Model Context Protocol (MCP) — an ATT&CK-style catalogue of agentic-system threats and defenses
- AgentGuard — Zero-Trust protocol for AI agents: identity, policy, mTLS, audit (Python SDK + Go server)
- spiffe-core · TraT — SPIFFE-based agent identity/attestation and Transaction Tokens for multi-agent workflows (TraT)
- sumit-mcp-server — Federated memory MCP server (live on HF Spaces)
- Vibe-Coder — An agent that builds Streamlit/FastAPI apps
- IRB Robotics Arm — Open-source image-recognition robotic arm (UN SDG3)